
Researcher: A Chat-Based Technical Research Agent
Background
Something I'd noticed was that getting up to speed on a technical topic properly takes a disproportionate amount of time. Reading around a subject to the point where I can make an informed decision or ask the right questions often takes several sessions of manual work, and the quality of what I find is inconsistent. The formal academic literature that tends to matter most is spread across paper databases that require their own search approach across evenings on google scholar.
I built this in early March 2026, during my placement at JLR, with dissertation research in mind. I return to Warwick in September 2026 to start a Master's dissertation, and that research phase involves a lot of domain-scanning: working out which avenues exist and whether they're worth pursuing before committing to one. A tool that could do a first pass on any topic and return something structured would compress that process considerably.
The depth system came from a real distinction in what I actually needed depending on the situation. Sometimes I'd come across a concept in passing at work and just want a quick explainer. Other times I'd be evaluating whether a specific approach was worth pursuing seriously. Those two needs are completely different, and collapsing them into a single query type would make the tool either too shallow or too expensive to run on casual questions.
How It Works
The workflow accepts a chat message. Lightweight models (GPT-4.1 Mini via OpenRouter) handle the input: one extracts the precise research topic from the natural-language phrasing, and a second classifies the intended depth. Depth falls into one of three tiers: Overview, Research, or Deep Report. If no depth signal is present, it defaults to Research.
Each tier configures a bundle of parameters: number of search iterations, number of document sections, target word count, and whether to include a sources section. An Overview runs two search iterations and produces around 400 words with no formal references. A Deep Report, on the other hand, runs ten iterations, produces 1,500 to 2,200 words in a structured report format, and includes numbered sources with links back to the original material.
The Information Agent (Claude Sonnet) receives the topic and depth configuration and conducts the research. It has two search tools: Tavily for general web results, and a custom arXiv tool for academic papers. Before searching, the agent decomposes the topic into sub-questions and distributes searches across them, compiling structured research notes once satisfied.
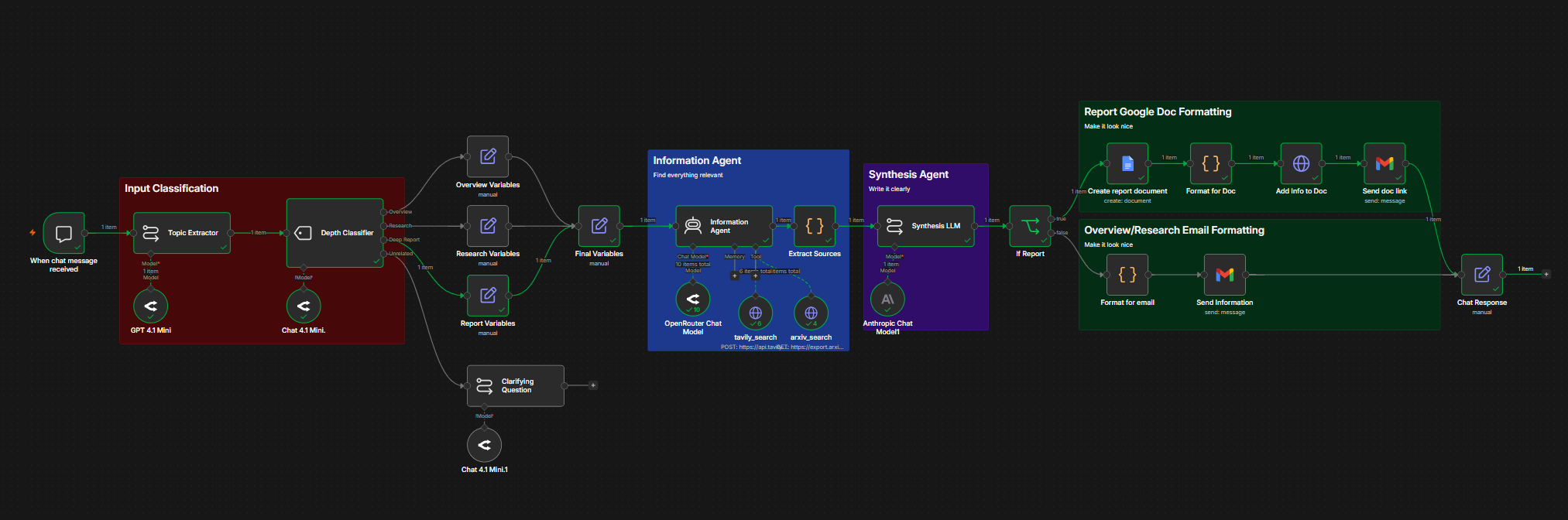 The n8n workflow canvas
The n8n workflow canvas
A dedicated Extract Sources node sits between the two stages. It reads the agent's completed research output and parses each tool observation to extract source URLs, separating content from sources into a clean object before anything reaches the writing stage.
The Synthesis LLM then receives the research notes and rewrites them into a polished document. It has no search access and works only from what the Information Agent found, which keeps its job focused on writing clearly rather than also managing search quality (minimising needless context bloat). It routes through OpenRouter rather than calling Anthropic directly, which avoids hitting the per-minute token ceiling that Deep Reports would otherwise trip on longer context windows. The output is a JSON object containing the formatted content. Deep Reports are created as a formatted Google Doc via the Docs API and a link is emailed; Overview and Research outputs go directly to email as styled HTML.
 A Research-depth email output
A Research-depth email output
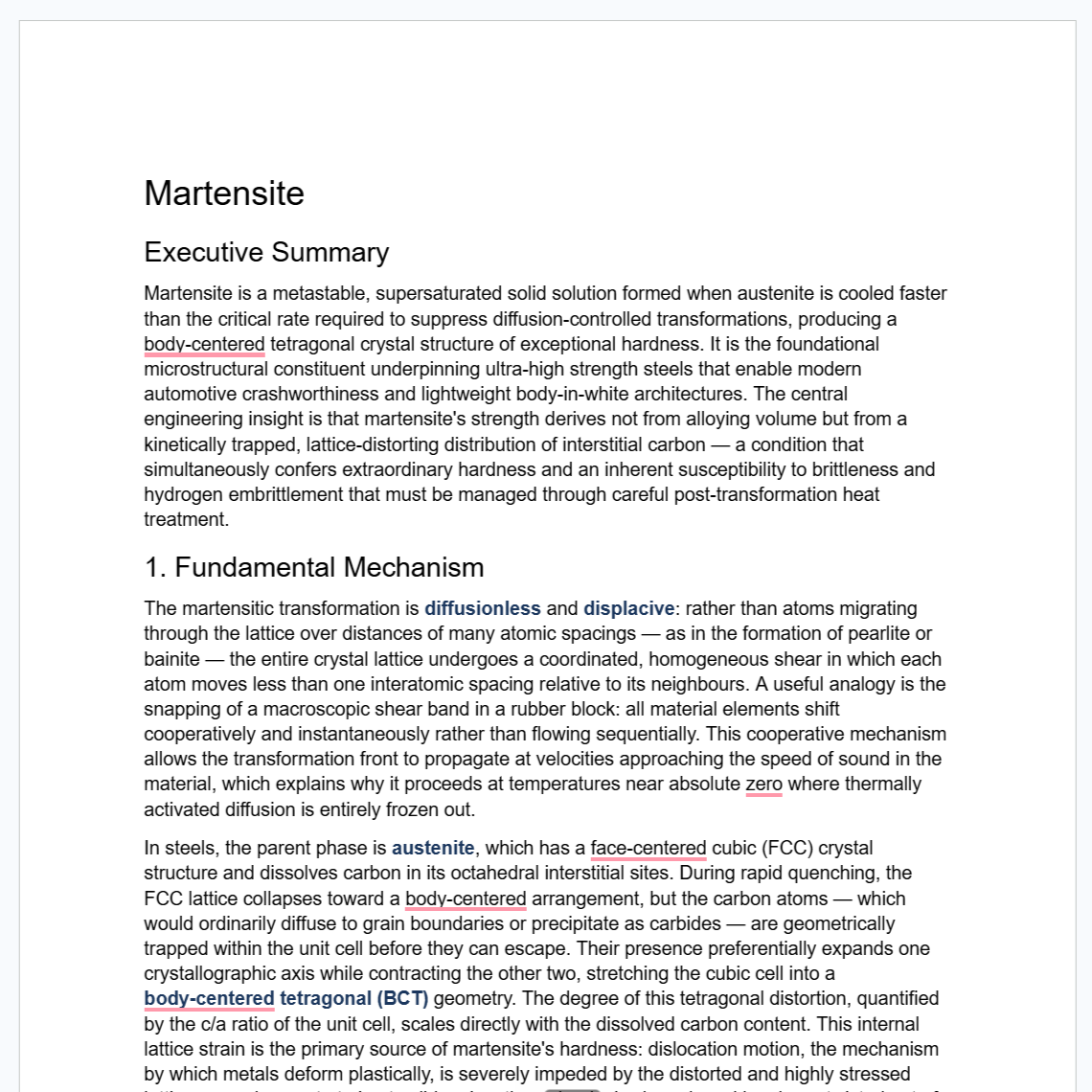 A Deep Report Google Doc
A Deep Report Google Doc
The arXiv Integration
The arXiv access is the part of this that makes the most practical difference, particularly for engineering and materials topics where the relevant literature is spread across academic papers rather than general web coverage.
The arXiv tool is an HTTP request node pointing at the arXiv export API. The query is AI-generated by the agent at runtime and supports Boolean operators and field prefixes (ti: for title, abs: for abstract), so the agent can construct targeted academic searches rather than keyword-only lookups. The API returns Atom XML, which the Extract Sources node parses downstream, pulling entry elements by regex to extract titles, IDs, and URLs before they reach the final document.
Running a Deep Report on piezoelectrics returned structured information that had taken me weeks to piece together manually from individual papers, along with a few details I hadn't come across at all. Being able to trace every finding back to a specific arXiv paper URL is the part that matters most for academic use: the sources are concrete and verifiable, not a summary with no provenance.
 The sources section of a Deep Report
The sources section of a Deep Report
The two-stage pipeline is what makes this work reliably. The Information Agent searches without worrying about formatting; the Synthesis LLM writes without worrying about sourcing. Combining those tasks in a single agent tends to produce shallow searches and rushed prose, because the context is split between two different jobs. Keeping them separate produces better results on both dimensions.
In Practice
Current use is intermittent: I run it when I need to get up to speed on something specific rather than on a schedule. The expectation is that it becomes much more central when I return to university for the dissertation, where the research phase involves evaluating multiple engineering domains before committing to a direction. That is exactly the case it was designed for.
The limitation I've run into outside engineering topics is that the prompts are calibrated for a technical engineering audience. They assume mechanical and materials literacy, use engineering analogies for unfamiliar concepts, and target a level of depth that can feel misaligned for software or business topics. Trying it on AI model architectures and industry developments produced results that were competent but noticeably optimised for the wrong audience.
The fix I'd want to implement is a topic classification step before the depth selection: a lightweight model classifies the subject area and selects the appropriate prompt configuration and structural template for that domain. That approach keeps output quality high across domains without needing one generic prompt that tries to work everywhere. The depth system handles how much research to do; a domain system would handle how to structure and frame what gets written.
More Projects

Study LLM: A RAG-Based Academic Knowledge Base
A multi-user platform that ingests university course materials and answers questions grounded in the uploaded content, with citations back to the source. Full backend complete, frontend in progress.

Daily Stock Update: An Evening Portfolio Briefing
An n8n workflow that reads a personal stock portfolio from a Google Sheet, pulls live prices and 30-day history from Alpha Vantage, pairs the data with Tavily sentiment research, and emails a formatted report every evening at 21:30.